If you’ve tried to learn machine learning before and bounced off a wall of equations and jargon, this article is for you. The core ideas behind machine learning are genuinely intuitive — they’re just often buried under technical language that makes them seem harder than they are.
Let’s fix that. By the end of this article, you’ll understand what machine learning actually is, how the main types work, what neural networks are, and how real machine learning systems are built in practice.
What Machine Learning Actually Means
Traditional programming works like this: a human writes explicit rules that a computer follows. Want to identify spam emails? A programmer writes rules: “If the email contains ‘Nigerian prince’ or ‘click here to claim your prize,’ mark it as spam.” The computer follows those rules exactly.
The problem is that writing rules for complex, messy real-world problems is extremely difficult. The world is full of edge cases and exceptions. What about spam that uses slightly different wording? What about a legitimate email that happens to mention a Nigerian prince?
Machine learning takes a different approach: instead of writing rules, you show the computer thousands of examples and let it figure out the patterns itself. You show it 100,000 emails labeled “spam” or “not spam,” and the machine learning algorithm finds the patterns that distinguish them — patterns that would take a human programmer years to codify explicitly.
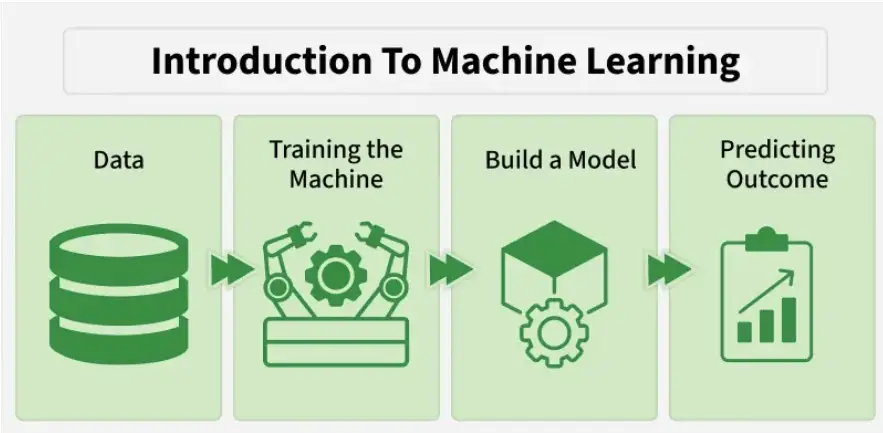
The precise definition: machine learning is a method of training a computer system to make decisions or predictions by learning from data, rather than being explicitly programmed with fixed rules.
The Three Main Types of Machine Learning
Supervised Learning: Learning With a Teacher
Supervised learning is the most common type and the most intuitive. You give the algorithm a dataset where every example is labeled — you already know the right answer. The algorithm learns to map inputs to outputs based on these labeled examples.
Here’s an analogy: imagine teaching a child to recognize dogs. You show them hundreds of photos and say “dog” or “not a dog” for each one. Over time, the child learns to identify the features that distinguish dogs from other animals — four legs, fur, snout shape, tail. They can then recognize a dog in a photo they’ve never seen before.
Supervised learning works the same way. Common applications include:
- Classification: Predicting a category — spam or not spam, cancer or benign, cat or dog
- Regression: Predicting a number — what will this house sell for? What will the temperature be tomorrow?
- Object detection: Finding and labeling objects in images
Unsupervised Learning: Finding Hidden Patterns
In unsupervised learning, you give the algorithm data without labels. There’s no right answer to learn from — the algorithm has to find structure in the data on its own.
The most common unsupervised learning task is clustering — grouping similar data points together. A business might use clustering to group their customers by behavior patterns (even without knowing in advance what those groups might be), which can then inform targeted marketing or product recommendations.
Another unsupervised technique is dimensionality reduction — finding a simpler representation of complex data. A dataset with 1,000 features might be reducible to 10 key features that capture most of the meaningful variation, making it much easier to visualize and work with.
Reinforcement Learning: Learning by Trying
Reinforcement learning is inspired by how animals and humans learn through trial and error. An agent (the ML model) takes actions in an environment, receives rewards for good actions and penalties for bad ones, and gradually learns to maximize its cumulative reward.
The most famous example is AlphaGo, DeepMind’s system that learned to play the board game Go better than any human player. It wasn’t programmed with Go strategy — it played millions of games against itself, learning which moves led to wins and which led to losses.
Reinforcement learning is also used to train robots to walk, optimize the movement of data center cooling systems, and increasingly to fine-tune large language models through the RLHF process discussed in our LLM article.
What Is a Neural Network?
You’ve probably heard neural networks mentioned constantly in discussions about AI. Here’s what they actually are.
A neural network is a type of machine learning algorithm loosely inspired by the structure of the human brain. The brain is made of billions of neurons connected by synapses — each neuron receives signals from many other neurons, processes them, and passes a signal on. Neural networks mimic this structure computationally.
An artificial neural network is made of layers of nodes (artificial neurons). Information flows from the input layer (the raw data) through one or more hidden layers (where the actual learning happens) to an output layer (the prediction). Each connection between nodes has a weight — a number that determines how much influence one node has on the next.
During training, these weights are adjusted billions of times to minimize the difference between the network’s predictions and the correct answers. A process called backpropagation figures out how each weight should change to improve accuracy. After training on enough examples, the network has adjusted its weights to capture the patterns in the data.
Deep learning simply means neural networks with many layers — typically dozens or hundreds. The “deep” refers to the depth of layers, not the intelligence. Deep neural networks excel at tasks involving unstructured data: images, audio, text, video. The layers learn increasingly abstract features — early layers might detect edges, middle layers might detect shapes, and later layers might detect entire objects.
How a Real ML Project Actually Works
Understanding the theory is one thing. Here’s what building a real machine learning project actually looks like in practice.
Step 1: Define the Problem
The first question is almost always: what specifically are you trying to predict or decide? “Make our product better with AI” is not a problem definition. “Predict which customers are likely to cancel their subscription in the next 30 days so we can intervene proactively” is. A clear, specific objective shapes everything that follows.
Step 2: Collect and Prepare the Data
Machine learning lives or dies by data quality. You need examples that are representative, labeled (for supervised learning), and plentiful enough for the algorithm to learn the relevant patterns. In practice, data preparation — cleaning, normalizing, handling missing values, removing duplicates — often takes 60-80% of the total project time. It’s unglamorous but critical.
Step 3: Choose and Train a Model
Depending on the problem, you’d select an appropriate algorithm — maybe a simple logistic regression, maybe a gradient boosting model, maybe a neural network. For most practical business problems, start simple. A simple model that works reliably beats a complex model that’s hard to understand and debug.
Training involves feeding your labeled data into the algorithm and letting it adjust its parameters to minimize prediction error. This is where the math happens, but modern libraries like scikit-learn, TensorFlow, and PyTorch handle the implementation.
Step 4: Evaluate Honestly
A model that performs perfectly on training data is essentially useless — it might have memorized the training examples rather than learned generalizable patterns. You evaluate models on data they’ve never seen before (the test set) to measure how well they actually generalize.
Common evaluation metrics include accuracy (percentage of correct predictions), precision, recall, and F1 score for classification problems, and mean squared error or mean absolute error for regression problems. Which metric matters depends on the context — for medical diagnosis, missing a true cancer case is much more costly than a false alarm, so you’d optimize for recall rather than raw accuracy.
Step 5: Deploy and Monitor
Getting a model working in a notebook is the beginning, not the end. Deploying it into a production system where it makes real decisions, and then monitoring its performance over time as the real world changes, is often the hardest part. A model trained on data from 2023 might become less accurate in 2025 as behavior patterns shift — this is called model drift, and catching it requires ongoing monitoring.
When Machine Learning Is and Isn’t the Right Tool
ML is genuinely useful for problems where patterns in data are too complex to encode as explicit rules, where you have enough labeled examples to train from, and where predictions can be made from available features.
ML is overkill (and often worse) for problems with simple rule-based solutions, problems where you have very little data, and problems where explainability matters more than accuracy — a bank needs to explain why it denied a loan application; a black-box model makes that hard.
The field has come an enormous way in the past decade, and the barriers to entry keep falling. Cloud ML platforms, pre-trained models, and high-quality libraries mean that a developer with no ML background can build and deploy a meaningful model in a day. But the fundamentals — good data, clear objectives, honest evaluation — matter as much as they ever did.